
Don’t try to build “AI agents” on day one. The path that actually works is a three-phase climb. Phase 1 is a chat-driven console where the human asks and the system answers. Phase 2 adds scheduled sentinel agents that run their own checks and post structured findings to a queue. Phase 3 adds event-driven specialist agents that propose actions a human approves with one click. Skipping phases is how teams build expensive demos that never reach production. Production gets its own platform surface from day one, not on day two.
“Agents” is the word everyone wants to use. It is also the word that gets ops teams in trouble fastest. An agent that runs unsupervised against a real database is a different problem than a chat assistant that answers questions. The discipline that makes the second possible is the discipline that earns you the first.
This is the maturity model I have built and am living through, in roughly that order. Phase 1 is in production. Phase 2 is partially deployed. Phase 3 is on the roadmap with one specialist agent in design. Each phase is a real graduation, not a marketing label.
The map
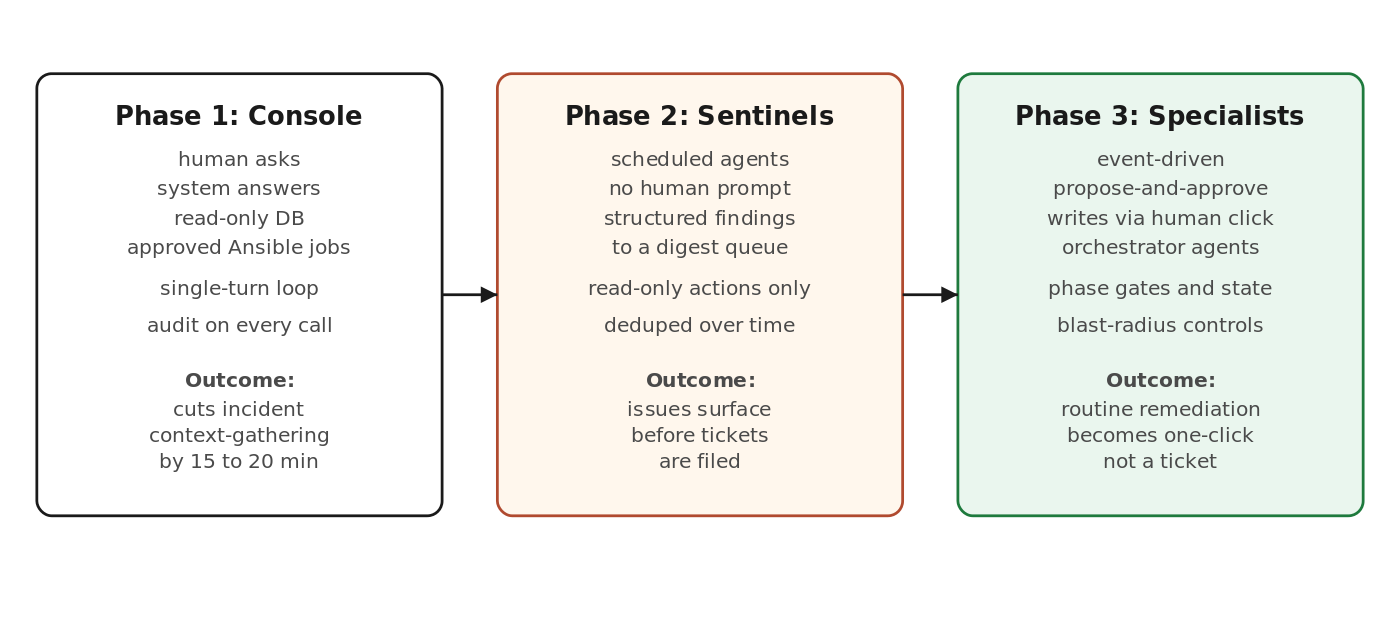
Three phases. Each is useful on its own. Each is the foundation for the next. Skipping is what kills the program.
Phase 1: the chat console
This is the foundation. A LibreChat-style front end. An LLM behind it. A small set of MCP servers exposing your database, your Ansible job catalog, and any other tools you trust. Read-only by default. Writes only through registered, validated playbooks. Audit on every tool call.
The reason this phase matters is not the chat experience. It is that you build the boring infrastructure, the guardrails, the registry, the audit pipeline, and the operational habits that every later phase depends on.
Phase 1 must-haves before you call it done.
- Tool calls go through MCP servers, not direct DB connections from the model.
- Every Ansible job is registered, named, and validated before submission.
- Production runs on a separate execution surface from day one. Even if you only use non-prod for now, the prod surface is a different controller, a different inventory, a different token. Not a flag.
- Audit log is a structured JSONL file, not the chat transcript.
- The most-asked recurring questions have curated answers in a query catalog or runbook collection that retrieval surfaces first.
- Identity passes through. The audit row says who really asked, not “service_account”.
Failure modes in Phase 1
The model invents query names that are not in the catalog. The fix is to refuse and ask the user to rephrase, not to let the model freelance SQL. The model double-submits Ansible jobs. The fix is per-turn dedup. The model picks the wrong environment when the user is sloppy. The fix is verified inventory aliases and an explicit “did you mean” structured error.
Most teams stop here, and that is fine. A good Phase 1 console pays for itself in saved minutes per incident. Not every team needs sentinels.
Phase 2: scheduled sentinels
Sentinels are agents that run on a schedule, with no human in the loop, and post structured findings to a queue or digest. They never write to systems. They only look, summarize, and report. Examples: a daily database health sentinel, a weekly tablespace growth sentinel, a daily cert expiry sentinel, a weekly OCI cost sentinel that flags idle resources.
The sentinel runs the same MCP tools the human chat console uses. That is the trick. You do not build new infrastructure for sentinels. You build a thin scheduler and a thin output formatter, and the sentinel uses what is already there.
Anatomy of a sentinel
# Pseudocode for a sentinel run
inputs:
schedule: "0 6 * * 1-5" # weekdays 6am
scope: "DEV*, TST, STAGE"
steps:
1. for each env in scope:
call run_named_query("db_health_summary", env)
call run_named_query("blocking_sessions", env)
call run_named_query("alert_log_recent_errors", env)
2. summarize findings (LLM call, tightly bounded)
3. emit structured record:
{ sentinel: "db_health", env: "TST",
severity: "warning",
findings: [...], evidence_link: "..." }
4. write to AGENT_EPISODIC table + digest queue
The output is structured. Not “here is a paragraph about your database”. A row in a table with severity, findings array, evidence link, and a stable sentinel identifier. The chat console can query it. The morning digest can format it. An on-call dashboard can color-code it.
Phase 2 must-haves.
- Sentinel runs are themselves audited. The audit row says
actor: sentinel/db_health, not a human.- Findings are deduplicated over time. The same warning two days in a row should not feel new.
- Severity is bounded. A sentinel cannot mark its own finding “critical” without rules. Critical is a configured threshold, not a model judgment.
- A platform-wide kill switch can disable all sentinels in seconds, with a runtime-agnostic flag the scheduler checks before every run.
- The episodic memory store (where findings live) is a real database table with retention rules, not a folder of JSON files no one reads.
Failure modes in Phase 2
Sentinels become noise. A daily digest with twenty warnings every morning gets ignored, and the one real warning gets ignored with it. The fix is dedup, severity discipline, and a hard cap on items per digest. Sentinels run during a maintenance window and report the maintenance as a critical issue. The fix is environment-scoped change-window awareness, which the sentinel reads from the same environment inventory the chat console uses.
Sentinels duplicate work humans already do. The fix is to retire the manual version once the sentinel is trusted. If the human still runs the daily check by hand “just to be sure”, the sentinel is not actually saving time.
Phase 3: event-driven specialist agents
This is where it gets interesting and where the discipline of the earlier phases pays off. A specialist agent reacts to an event, pulls together the context, decides what action would resolve it, and proposes that action to a human via a one-click approval. On approval, it submits the same registered Ansible job the chat console would have used.
Examples: a tablespace specialist that proposes a datafile add when a sentinel fires a tablespace warning. A patch orchestrator that proposes the next wave of OS patches based on the change calendar. A concurrent manager remediation specialist that proposes restarting a stuck CM after correlating recent errors with prior incident summaries.
Why this is hard
Specialists need state. They are not single-turn. A patch orchestrator does pre-checks, then proposes, waits for approval, executes, monitors, runs post-checks, and only then closes the loop. That is a graph, not a chain. You need a runtime that supports phase gates, retries, persistent state, and explicit human-approval steps.
Most teams reach for an orchestration framework here. That is fine. The important part is that the orchestrator runs in a place that fits your operational model. A managed runtime if you have one. A controlled VM if you do not. The choice is mostly about who patches it and who watches its logs, not about the framework’s feature list.
Phase 3 must-haves.
- Every action a specialist takes corresponds to a registered Ansible job. Specialists do not get a custom action surface.
- Approval is a real signal. A user clicking “approve” is logged with their identity, the specific proposal, and the timestamp. That row is what justifies the action.
- Production specialists run on the production execution surface. Non-prod specialists run on the non-prod surface. They are not the same service with a flag.
- Each specialist has a documented blast radius. “What is the worst that can happen if this fires twenty times in an hour?” If the answer is bad, you add a rate limit.
- Orchestrators that hold state have phase gates. The gate is a code-level check, not a polite suggestion to the model.
Failure modes in Phase 3
The specialist proposes the same fix three different ways and the human approves the wrong one. The fix is to constrain the proposal format and only ever offer one action per finding. The specialist takes too long to gather context and the on-call person fixes it manually before the proposal lands. The fix is to time-box the gather phase and emit a partial proposal if the timer expires.
The specialist drifts from the playbook over time as people add bespoke logic to the orchestrator. The fix is the same as for chat: every action goes through the registered Ansible job. The orchestrator decides which job to call, not what the job does.
Production is a separate platform from day one
This is the rule that survives every phase. Even in Phase 1, when there is no production access from chat, the production execution surface exists as a different controller. By Phase 3, you will be glad it does. Anything that ever touches production runs on its own platform, with its own credentials, its own queue, its own audit pipe. There is no “shared with extra checks” path. The shared path is the bug.
The cost of this is one extra Semaphore controller and a duplicated set of templates. The benefit is that a Phase 3 mistake in non-prod cannot reach production at all, ever, by design. That is worth a controller.
Where to invest in the boring stuff
The visible work is the chat UI and the agents. The work that determines whether any of it succeeds is unglamorous.
- Identity propagation. Spend time making sure every tool call lands in the audit log with the real user. This pays back forever.
- Inventory truth. A verified mapping from logical environment names to actual Ansible inventory groups. Not guessed. Built from the inventory files.
- Audit pipeline. Append-only, structured, queryable. Not a chat log. Not a folder of files. A real pipeline.
- Kill switch. A single flag that disables all autonomous behavior in seconds. Tested. Documented. Practiced.
- Observability. LLM-step tracing for “why did the model pick that”. BI dashboards for “is the program saving time”. Runtime monitoring for “is a sentinel silent for the third hour in a row”. Three different tools because they answer three different questions.
Models and budgets
Use the cheap-and-fast model by default. Phase 1 chat queries with curated retrieval almost never need a frontier model. Reserve the expensive tier for the orchestrator phase where reasoning over multi-step state actually pays back. Pin the model family at the platform level, not per-feature, and revisit it on a schedule. The right answer in six months is probably a different model than the right answer today.
Budget for retrieval and embeddings, not just inference. A useful Phase 1 console can run on a few hundred dollars a month of inference plus the ATP database you already own. A Phase 3 program with several specialists doing event-driven work doubles that. None of it requires a separate VM you do not already have, if you reuse your existing database for episodic memory.
What this maturity model does not promise
It does not promise that you will replace DBAs. You will not. The work shifts. Less time on health sweeps and ticket triage, more time on the judgment calls that actually need a human. If your goal is headcount reduction, this program is a poor investment and you will be disappointed.
It also does not promise that the model will get smarter on its own. The model gets more useful as you curate. The catalog gets sharper, the runbooks get tighter, the sentinels get less noisy, the specialists get more accurate. Curation is the work. Buying a more powerful model and skipping the curation will not save you.
A 90-day starter plan
- Days 1 to 30. Stand up Phase 1. One MCP server for the database, one for Ansible. Twenty queries in the catalog. Five Ansible jobs in the registry. Audit log writing to a real table. Use it daily for one team’s incidents.
- Days 31 to 60. Add identity propagation. Add the kill switch. Build the morning digest format. Add ten more catalog entries based on what you saw the team ask in Phase 1.
- Days 61 to 90. Pick one sentinel. Daily DB health is the easy default. Run it for two weeks reading-only. Tune dedup. Add severity rules. Once it stops creating noise, add a second sentinel.
Do not start a Phase 3 specialist before you have lived with two stable sentinels for at least four weeks. The patience you build during that wait is the same patience you need to keep an event-driven agent honest in production.
Further reading
- Anthropic, Model Context Protocol specification.
- Google SRE book chapter on toil reduction, for the framing of “promote toil to automation”.
- Oracle, AI Vector Search in Oracle Database 23ai, for the episodic and RAG storage layer.
- OCI documentation on Generative AI service and Responses API for hosted model surfaces.
- From Chat to Autonomous Agents: A Maturity Model for DBA AIOps - April 27, 2026
- Query Catalog Pattern for Natural Language to SQL: Frontmatter-Driven Routing - March 22, 2026
- Safe Ansible Automation for AI Chat: A Guardrail Framework - February 3, 2026