
Letting a chat model trigger Ansible jobs is fine. Letting it trigger Ansible jobs without a registry, a force gate, prod separation, dedup, and a real audit log is how you take an environment down. This is the framework I use in a live chat-driven Oracle ops console: registry-driven job exposure, multi-play playbooks with pre-checks, hard production isolation, per-turn dedup, and intent routing for safe read-only checks. The patterns are simple. Skipping any one of them is what hurts.
Connecting a large language model to Ansible is the easy part. Most teams stop there and discover the problems the hard way. This is the framework I have settled on after running the system in a real ops environment for several months. It is opinionated. Every piece exists because something went sideways without it.
The architecture in one picture
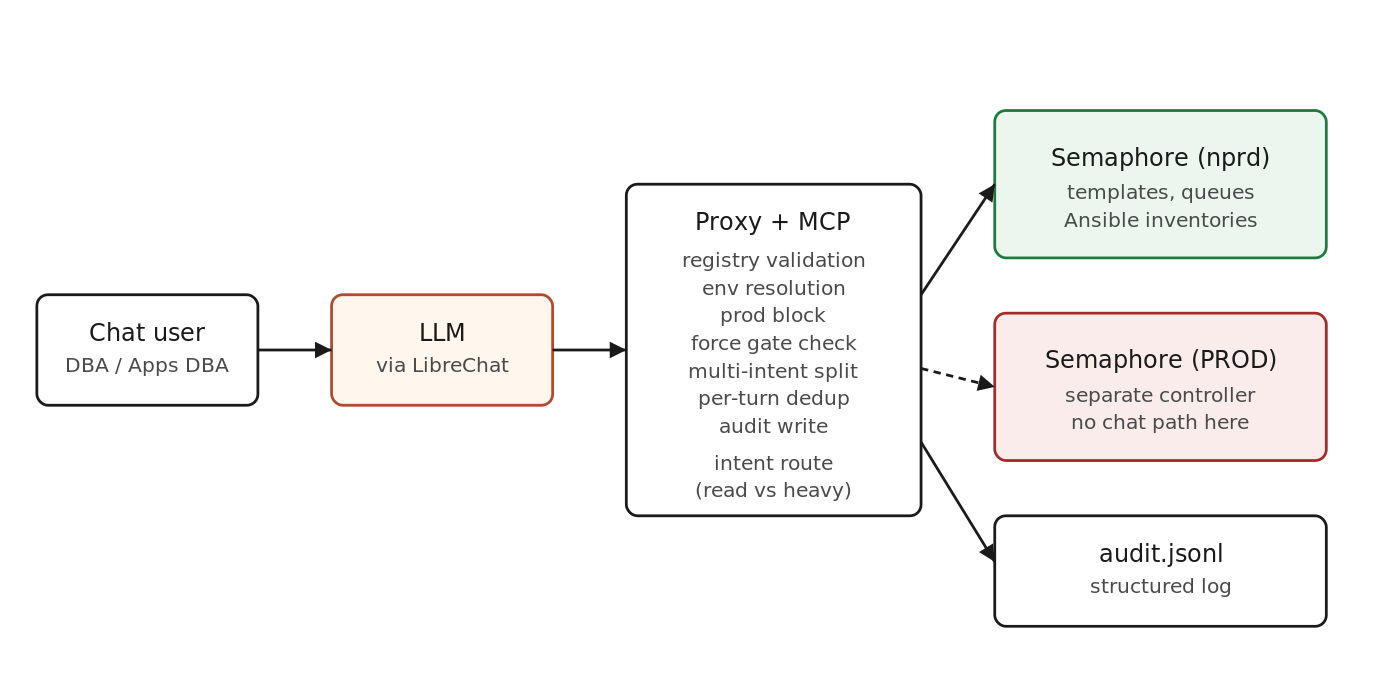
Solid arrows are normal flow. Dashed line into the prod controller is intentionally absent in the chat path. Production is a different surface, not a flag.
Layer 1: a registry, not free-form playbook calls
Do not let the model name a playbook directly. The model picks from a registry of named jobs, and each entry in the registry tells the proxy exactly what is allowed.
# ansible_registry.yaml (excerpt)
apps_apache_restart:
description: "Restart the Apache front-end on the named environment."
domain: appsdba
template_id: 142
allowed_vars: ["env_target", "force"]
use_global_target_map: true
confirmation_required: true
intents:
- "restart apache"
- "bounce apache"
- "apache restart"
A registry buys you four things at once. The model only sees jobs you have approved. The variables passed in are constrained. Intent aliases let natural language map to the right job without prompt-engineering acrobatics. Domain tags let you filter the menu when you list jobs (“show me only OCI jobs”).
Naming convention matters more than it sounds. I use [Target]_[Component]_[Action], action verb last. So apps_apache_restart, not restart_apache_in_apps. The model picks the right one faster when names line up consistently.
Layer 2: every operational playbook is multi-play with a pre-check
Single-play playbooks are fine for read-only checks. Anything that writes should be structured as four plays in one file:
- PRE-CHECK. Does the target system look like what the playbook expects. If not, fail here.
- ACTION. The mutation itself. Runs only if pre-check passed, or if force is set.
- POST-CHECK. Confirm the action did what it was supposed to do.
- EVIDENCE. Always runs. Drops a structured record into a known location.
Ansible stops on the first failed play, which is exactly what you want. The structure is more verbose than a one-shot script but it makes every job recoverable, auditable, and rerun-safe.
Layer 3: the force gate
Pre-checks fire false positives. A playbook that refuses to run because the pre-check is wrong is worse than no pre-check at all, because the on-call person now distrusts the whole system. The escape hatch is a force=true variable that bypasses the gate, with strict rules.
Force is not a normal flag. Every playbook that supports it must:
- Gate the action play with
when: precheck_failed | bool and not (force | bool).- Log
FORCE OVERRIDE USEDin the evidence file, with the user identity that requested it.- Include
forceinallowed_varsin the registry entry.- Mark the registry entry
confirmation_required: true.- Return
"force_override": truein the MCP response so the chat layer can show it.
What force never bypasses: syntax errors, missing required variables, unreachable hosts, or anything the user did not explicitly opt into. The model cannot set force on its own. The user has to type the word, and the proxy treats it as a separate confirmation step.
Layer 4: production is a different platform, not a flag
This is the rule that I see violated most often and regretted most quickly. Do not put production behind an if env == "PROD": deny check in the same proxy. That is a single character away from a disaster. Use a separate Semaphore controller for production, with its own inventory, its own templates, its own queue, and its own credentials. The chat-driven path is wired to the non-prod controller only.
If you eventually want chat-driven actions in production, you build a different surface for it. You do not extend the non-prod surface with a flag. The blast radius of a bug in shared code is the entire fleet.
The proxy still has a defense-in-depth check that refuses to ship anything to a host name or variable matching \bprod\b, with an explicit allow list of patterns that look like prod but are not (think productivity_app or product_catalog). That belt is cheap. The suspenders is the separate controller.
Layer 5: per-turn dedup of submitter calls
Models like to “make sure” by calling the same tool twice. In chat, that turns into the same Ansible job submitted twice in three seconds. You do not want two parallel restarts of the same Apache instance.
The proxy enforces one Ansible-submit call per model turn. Repeated run_ansible_job tool calls inside the same assistant response are deduplicated before execution. If the second call would target a job that is already running, the proxy returns a structured duplicate_blocked response. That is not an error. It is expected behavior. The chat layer surfaces it as “that job is already running, ask me to check status”.
Without this, you will spend afternoons explaining to people why their playbook ran twice.
Layer 6: intent routing so simple checks stay simple
A user asking “what is the ulimit for the apps user on the TST app server” should not trigger a full linux_server_health_check. It should run a short read-only command through a tiny linux_read_only_command_runner template that knows how to run a fixed allowlist of commands.
| Intent | Wrong route | Right route |
|---|---|---|
| “check ulimit for applmgr” | linux_server_health_check (full diagnostic) | linux_read_only_command_runner with su - applmgr -c 'ulimit -a' |
| “is df clean” | linux_server_health_check | linux_read_only_command_runner with df -h |
| “full health sweep” | three small checks fired in parallel | linux_server_health_check (correct here) |
Routing keeps the heavy templates for what they were built for. Read-only one-shots stay cheap. The audit log stays clean. The user sees an answer in two seconds instead of forty.
Layer 7: multi-intent handling so the model does not silently drop tasks
Real users send messages like “check apache on TST and STAGE, and also tell me top waits in DEV1”. A naive setup picks one of those, runs it, and ignores the rest. The user does not notice until they audit later.
The proxy detects multi-intent messages with five patterns: numbered lists, bullet lists, plain multi-line lists with action verbs, multiple question marks, and explicit connectors like “and also”. When detected, it injects a system-prompt override that lists the sub-tasks and tells the model to make one tool call per task with isolated environment and parameters. It also relaxes the per-turn dedup for that turn so each sub-task can run.
The cap is five sub-tasks. More than that and the proxy asks the user to split the message. That limit exists to keep one runaway message from queuing thirty jobs at once.
Layer 8: structured audit, not chat transcripts
Every job submission, every dedup block, every force override, every multi-intent split, every prod-pattern reject lands in a JSON line file with these fields at minimum:
- timestamp, user identity, model, conversation id
- tool name and template id
- resolved environment limit, original requested limit
- variables passed (excluding any secret material)
- outcome (submitted, duplicate_blocked, validation_failed, prod_blocked)
- force override flag
- Semaphore task id, if submitted
This is the file your security review wants to see. It is also the file that lets you debug behavior six weeks after a weird incident. Do not rely on the chat transcript. The transcript is for humans. The audit log is for everyone else.
The validation order that matters
Inside the proxy, the order of checks is not arbitrary. Get this wrong and the wrong error reaches the user.
- Tool name is in the registry. If not, refuse.
- Variables passed are in
allowed_vars. If extras, refuse. - Environment string resolves through the verified inventory alias map. If not, return a list of close matches as a structured error so the model can ask the user.
- Resolved limit does not match the prod pattern. If it does, refuse with the prod block message.
- If
confirmation_requiredand the user has not confirmed, return a confirmation prompt instead of executing. - If a duplicate is already running, return
duplicate_blocked. - Submit to Semaphore. Capture the task id. Write the audit record.
The reason this order matters: env resolution must happen before prod check, otherwise a logical alias that resolves into a prod inventory group bypasses a check that only looks at the original string. Ask me how I learned this.
What I will not do
Some patterns sound clever and are not. I do not let the model write Ansible variables to a file the playbook reads. I do not let the model decide on its own to escalate to a more powerful template. I do not let the model retry a failed submit on its own. I do not let the model bypass the registry by “describing” what it wants done. Every one of those crosses the line from natural language layer to decision-maker, and the decision-maker should be the proxy or the human.
What this framework does not give you
It does not give you good playbooks. You still need to write them. It does not protect you from a model that picks the wrong job from the registry. It does not stop a confused human from typing “force=true” when they should have read the pre-check error. It does not replace change control. It is a floor, not a ceiling.
What it does give you is a system you can show your security team without flinching, and a set of failure modes that are explicit and structured rather than weird and hidden. That is most of the value.
A short maturity check
- Can the model name any playbook it wants, or only registered ones?
- Does every operational playbook have a pre-check it can fail on?
- Is force support uniform, audited, and confirmation-gated?
- Is the production execution plane a different controller, not a flag?
- Is per-turn dedup in place for submitter calls?
- Does multi-intent get split into independent calls, or does the model pick one and ignore the rest?
- Are simple read-only asks routed to a read-only runner, not a heavy template?
- Is there a structured audit log, separate from the chat transcript?
If you cannot answer yes to all eight, that is your roadmap. Pick the gap that hurts the most and close it first.
Further reading
- Ansible documentation on playbook strategies and play-level fail handling.
- Semaphore UI documentation on templates, environments, and the API.
- OWASP guidance on LLM application security, especially insecure tool use.
- From Chat to Autonomous Agents: A Maturity Model for DBA AIOps - April 27, 2026
- Query Catalog Pattern for Natural Language to SQL: Frontmatter-Driven Routing - March 22, 2026
- Safe Ansible Automation for AI Chat: A Guardrail Framework - February 3, 2026