Below is basic diagram of Data Guard Physical Standby Database:
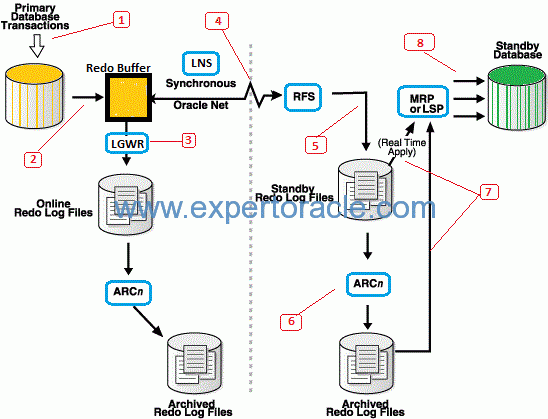
PHYSICAL STANDBY DATA FLOW
Let us understand how the data flows in data guard setup as described above by Points 1 to 8 :
Point 1) On Primary Database, Transactions starts. All the buffer cache locks (exclusive locks) that are required for the transaction are acquired.
Point 2) On Primary Database, the redo blocks that describes the changes (or change vectors) are generated and stored in the processes’ Program Global Area (PGA). After successfully acquiring the redo allocation latch, space is then allocated in the redo log buffer. The redo generated then gets copied from the processes’ PGA into the redo log buffer.
Point 3) On Primary Database, The oracle foreground process tells the LGWR to flush the redo log buffers to disk. Remember that the database blocks in the database have not yet been updated with DML changes. The LGWR flushes the redo buffers to the ORL and acknowledges the completion to the session. At this point, the transaction is persistent on disk. No commit has occurred thus far.
At some future time, the database buffers that were previously changed will be written to disk by the database writer process (DBWR) at checkpoint time. This point is not marked in above diagram.
Note that before the DBWR process has flushed the database buffers to disks, the LGWR process must have already written the redo buffers to disk. This explicit sequence is enforced by the write-ahead logging protocol.
Also The ARCH process on the primary database archives the ORLs into archive log files. This point is also not marked in the above diagram.
Point 4) On Primary Database, the LNS process reads the recently flushed redo from the redo log buffer and sends the redo data to the standby database using the redo transport destination (LOG_ARCHIVE_DEST_n) that we defined during standby database creation. We are using ASYNC transport method, so the LGWR does not wait for any acknowledgment from the LNS for this network send operation. It does not communicate with the LNS except to start it up at the database start stage and after a failure of a standby connection.
Point 5) On Standby Database , the RFS reads the redo stream from the network socket into the network buffers, and then it writes this redo stream to the SRL.
Point 6) On Standby Database, The ARCH process archives the SRLs into archive log files when a log switch occurs at the primary database. The generated archive log file is then registered with the standby control file.
flow involves three distinct phases, as follows:
Point 7) On standby database, the actual recovery process starts from this step. The managed recovery process (MRP) will asynchronously read ahead the redo from the SRLs or the archived redo logs (when recovery falls behind or is not in real-time apply mode). The blocks that require redo apply are parsed out and placed into appropriate in-memory map segments.
Point 8) On standby database, the MRP process ships redo to the recovery slaves using the parallel query (PQ) interprocess communication framework. Parallel media
recovery (PMR) causes the required data blocks to be read into the buffer cache, and subsequently redo will be applied to these buffer cache buffers.
At checkpoint phase, the recently modified buffers (modified by the parallel recovery slaves) will be flushed to disk and also the update of datafile headers to record checkpoint completion.
PHYSICAL STANDBY DATABASE RELATED PROCESSES
All the important processes are marked by blue box in the above diagram
On the Primary Database:
LGWR : The log writer process flushes log buffers from the SGA to Online Redo Log files.
LNS : The LogWriter Network Service (LNS) reads the redo being flushed from the redo buffers by the LGWR and sends the redo over network to the standby database. The
main purpose of the LNS process is to free up the LGWR process from performing the redo transport role.
ARCH : The archiver processes archives the ORL files to archive log files. Up to 30 ARCH processes can exist, and these ARCH processes are also used to fulfill gap resolution requests. Note that one ARCH process has a special role in that it is dedicated to local redo log archiving only and never communicates with a standby database.
On the Standby Database:
RFS : The main objective of the Remote File Server process is to perform a network receive of redo transmitted from the primary site and then writes the network buffer (redo data) to the standby redo log (SRL) files.
ARCH : The archive processes on the standby site perform the same functions performed on the primary site, except that on the standby site, an ARCH process generates archived log files from the SRLs.
MRP : The managed recovery process coordinates media recovery management. Remember that a physical standby is in perpetual recovery mode.
Basically we can categorize physical standby database into three major components:
1) Data Guard Redo Transport Services
– To transfer the redo that is generated by the primary database to the standby database.
Point 4 and 5 in the above diagram are where Redo Transport works.
2) Data Guard Apply Services
– To receive and apply the redo sent by Redo Transport Services to the standby database.
Point 7 and 8 in the above diagram are where Redo Apply works.
3) Data Guard Role Management Services
– To assist in the database role changes in switchover and failover scenarios.
This service works in the background and takes care of switchover/failover scenarios


- Oracle Multitenant DB 4 : Parameters/SGA/PGA management in CDB-PDB - July 18, 2021
- Oracle Multitenant DB 3 : Data Dictionary Architecture in CDB-PDB - March 20, 2021
- Oracle Multitenant DB 2 : Benefits of the Multitenant Architecture - March 19, 2021
wat is the difference between foreground and background process
Hi,
Hope this may useful.
https://ora-data.blogspot.in/2017/01/dataguard-setup-in-oracle.html
Thanks,
Excellent article. Simple and yet explained in detail. Thanks.
Very well written posts.Please do write a post on RAC to Single instance Standby and switchover and failover scenarios.
Fetch Archive Log (FAL) process has not been mentioned – Maybe since it’s part of latest Oracle versions? Otherwise as usual, a nice article.